
Implementation#
DevCGSolver implements the preconditioned CG method entirely on the GPU using
a CUDA Conditional Graph — a conditional while graph node that keeps the
convergence loop GPU resident with zero per iteration CPU work.
The implementation has two steps.
Step 1 — Capture the iteration body as a CUDA graph (goal: eliminate launch overhead)#
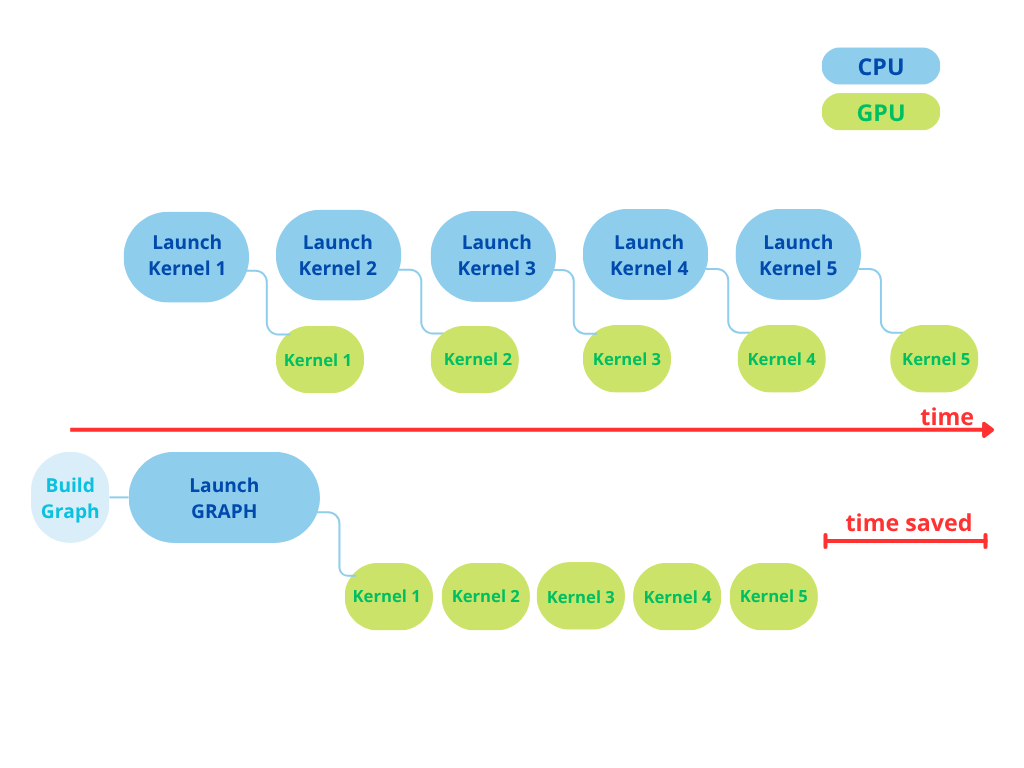
Inspired by: NVIDIA Corporation, "CUDA Graphs", OLCF Training, 2021.
The sequence of CG iteration is captured once using CUDA stream capture:
cudaStreamBeginCapture(stream, cudaStreamCaptureModeGlobal);
// launch all iteration kernels on stream
cudaStreamEndCapture(stream, &bodyGraph);
cudaGraphInstantiate(&bodyExec, bodyGraph, ...);
The captured body graph replays the full iteration with minimal CPU overhead —
no per-kernel cudaLaunchKernel call, just one cudaGraphLaunch.
Step 2 — Wrap in a CUDA Conditional While node (eliminate CPU convergence checks)#
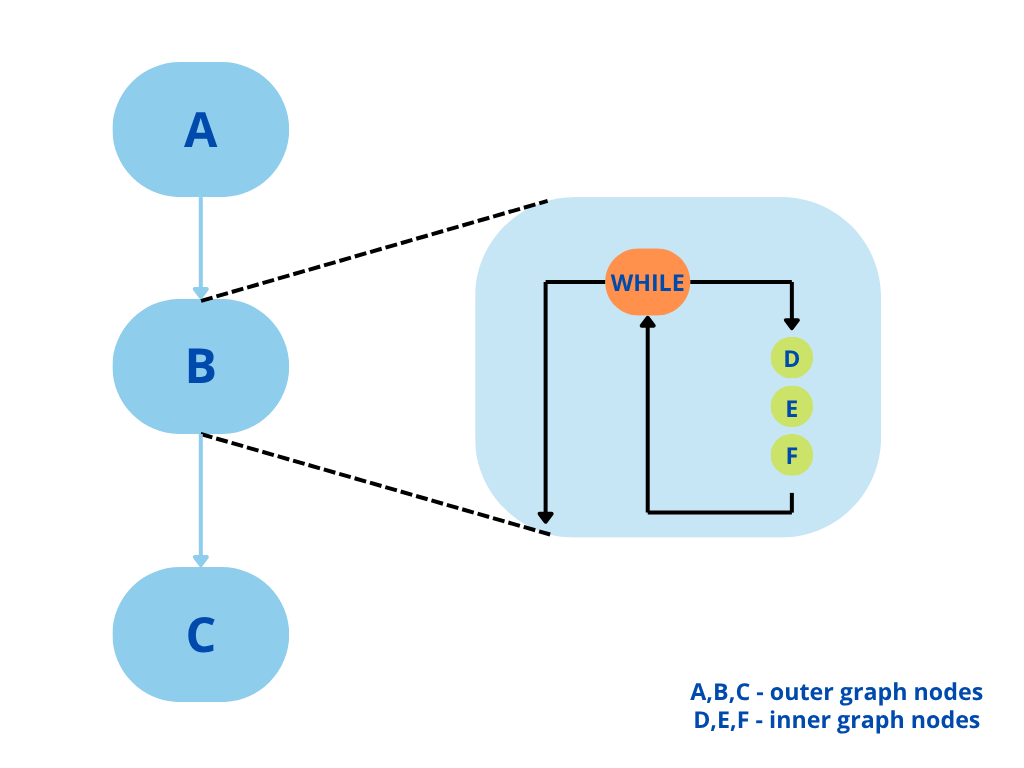
Inspired by: S. Jones, "CUDA Graphs Conditional Nodes", NVIDIA / HiHAT, Aug 2024.
A standard graph replays a fixed number of times. To loop until convergence, the body graph is embedded inside a CUDA Conditional While node:
cudaGraphCreate(&whileGraph, 0);
cudaGraphConditionalHandleCreate(&condHandle, whileGraph, 1, ...);
cudaGraphAddNode(&whileNode, whileGraph, condHandle, ...);
cudaGraphAddChildGraphNode(&bodyNode, whileGraph, bodyGraph);
cudaGraphInstantiate(&whileExec, whileGraph, ...);
The Conditional While node re-executes its body graph as long as a GPU-side flag is 1.
ConvergenceCheckKernel#
At the end of each iteration body, ConvergenceCheckKernel computes norm of r and
sets the conditional flag directly on GPU:
__global__ void ConvergenceCheckKernel(
cudaGraphConditionalHandle handle,
const double* norm_sq, double tol_sq)
{
unsigned int val = (*norm_sq > tol_sq) ? 1 : 0;
cudaGraphSetConditional(handle, val);
}
No value is transferred to the CPU. The CPU launches the graph once and waits for it to finish — all convergence decisions happen on GPU.